Implementation and Performance Comparison of Sequential and Parallel Merge Sort Does Parallel Merge Sort Really Win? Implementing and Comparing from Scratch
Does Parallel Merge Sort Really Win?
Sorting is one of the most fundamental problems in computer science. From databases and operating systems to large-scale data processing and scientific computing, efficient sorting often determines overall system performance.
Among classical sorting algorithms, Merge Sort stands out. It offers a guaranteed time complexity of O(n log n), behaves predictably regardless of input distribution, and follows a clean divide-and-conquer strategy.
Because of this structure, merge sort is often presented as an ideal candidate for parallel execution.

This naturally raises an important question:
If merge sort is so easy to parallelize, does parallel merge sort always outperform sequential merge sort?
In this article, we explore this question by:
- Understanding merge sort conceptually
- Implementing sequential and parallel merge sort from scratch
- Running controlled performance experiments
- Analyzing why parallel merge sort sometimes wins — and sometimes doesn’t
The goal is not just to show results, but to understand why those results occur.
Merge Sort as a Divide-and-Conquer Algorithm
Merge sort is built on a very simple idea:
- Divide the array into two halves
- Recursively sort each half
- Merge the two sorted halves
This process continues until the subarrays reach size 1, which are trivially sorted.
Why Merge Sort Is Predictable
At every level of recursion:
- The array is split in half
- The merge operation processes all elements once
This results in:
- log n levels of recursion
- O(n) work per level
So regardless of the input, merge sort always runs in: O(nlogn)
This predictability is one of merge sort’s biggest strengths.
Sequential Merge Sort: The Baseline
In sequential merge sort, everything happens on a single thread.
How It Works
- Recursive calls execute one after another
- Each call waits for its children to complete
- Merging is performed sequentially
Even though left and right subarrays are logically independent, the sequential implementation does not exploit this independence.
This makes sequential merge sort an excellent baseline for comparison.
Why Merge Sort Looks Perfect for Parallelism
At each recursive step, merge sort creates two independent subproblems:
- Sort the left half
- Sort the right half
These two tasks:
- Do not depend on each other
- Do not share data
- Can be executed simultaneously
This makes merge sort look naturally parallel.
So the idea behind parallel merge sort is simple:
Why not sort both halves at the same time using multiple cores?
Parallel Merge Sort: The Core Idea
In parallel merge sort, recursive calls are executed concurrently using multiple threads.
Conceptually:
- The recursion tree remains the same
- Independent branches are executed in parallel
- The merge step combines results after synchronization
In an ideal world with unlimited processors and zero overhead, parallel merge sort could approach O(n) time.
But real systems are not ideal.
Parallelism Comes With Hidden Costs
Parallel execution introduces overhead that theoretical analysis often ignores.
Thread Creation Overhead
Creating threads is expensive. It involves:
- Memory allocation
- Scheduling
- Context switching
For small subarrays, this cost can exceed the benefit of parallel execution.
Synchronization Overhead
Parallel threads must be synchronized before merging:
- Threads must wait for each other
- Join operations introduce latency
This waiting time adds up across recursive calls.
Memory and Cache Effects
Parallel threads often share memory:
- Cache coherence traffic increases
- Memory bandwidth becomes a bottleneck
This limits real-world scalability.
From Theory to Implementation
To fairly compare sequential and parallel merge sort, we implement both from scratch using C++.
The key goals of the implementation are:
- Same merge logic
- Same input data
- Controlled parallelism
- Realistic performance measurement
C++ Implementation
Merge Function
void merge(vector<int>& arr, int left, int mid, int right) {
vector<int> temp;
int i = left, j = mid + 1;
while (i <= mid && j <= right)
temp.push\_back(arr\[i\] <= arr\[j\] ? arr\[i++\] : arr\[j++\]);
while (i <= mid) temp.push\_back(arr\[i++\]);
while (j <= right) temp.push\_back(arr\[j++\]);
for (int k = 0; k < temp.size(); k++)
arr\[left + k\] = temp\[k\];
}The same merge function is used for both versions to ensure a fair comparison.
Sequential Merge Sort
void sequentialMergeSort(vector<int>& arr, int left, int right) {
if (left >= right) return;
int mid = left + (right - left) / 2;
sequentialMergeSort(arr, left, mid);
sequentialMergeSort(arr, mid + 1, right);
merge(arr, left, mid, right);
}This is the standard recursive implementation running on a single thread.
Parallel Merge Sort
const int PARALLEL\_THRESHOLD = 10000;
void parallelMergeSort(vector<int>& arr, int left, int right) {
if (left >= right) return;
if (right - left < PARALLEL\_THRESHOLD) {
sequentialMergeSort(arr, left, right);
return;
}
int mid = left + (right - left) / 2;
thread t1(parallelMergeSort, ref(arr), left, mid);
thread t2(parallelMergeSort, ref(arr), mid + 1, right);
t1.join();
t2.join();
merge(arr, left, mid, right);
}Why the Threshold Matters
Parallelizing very small subarrays is inefficient.
The threshold prevents unnecessary thread creation and keeps overhead under control.
Experimental Setup
To ensure fairness and reproducibility:
- Random arrays are generated with a fixed seed
- Each input size is tested 5 times
- Average execution time is measured
- Timing uses std::chrono::steady_clock
vector<int> generateRandomArray(int size) {
vector<int> arr(size);
static mt19937 gen(42);
uniform\_int\_distribution<> dist(1, 1'000'000);
for (int& x : arr) x = dist(gen);
return arr;
}Array sizes range from 10 elements to 1,000,000 elements.
Performance Results and Visualization
The execution times are visualized using Python.
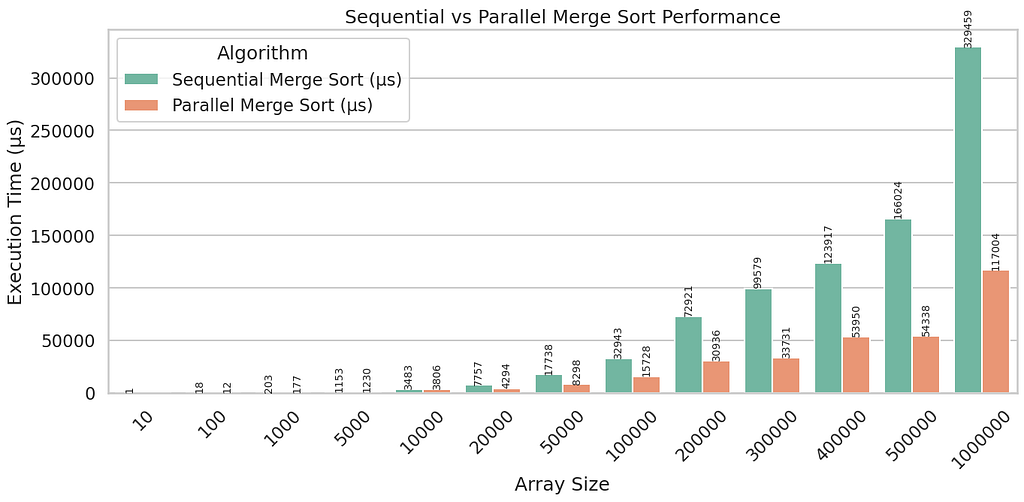
Figure: Sequential vs Parallel Merge Sort execution time (µs) across varying input sizes
The visualization clearly reveals performance trends across input sizes.
Interpreting the Results
Small Input Sizes
- Sequential merge sort is faster
- Parallel overhead dominates
- Thread creation cost outweighs benefits
Parallel merge sort performs worse here.
Medium Input Sizes
- Performance becomes competitive
- Parallel version begins to catch up
- Results depend heavily on the threshold value
This is the region where intuition often breaks.
Large Input Sizes
- Parallel merge sort consistently outperforms sequential
- Overhead is amortized
- Multiple cores are effectively utilized
However, the speedup is sublinear, not proportional to the number of cores.
Why Parallel Merge Sort Does Not Scale Perfectly
Several factors limit scalability:
- Sequential merge steps
- Synchronization overhead
- Memory contention
- Load imbalance across threads
This is a practical demonstration of Amdahl’s Law.
Does Parallel Merge Sort Really Win?
The honest answer is:
Yes — but only under the right conditions.
Parallel merge sort wins when:
- Input size is large
- Parallelism is carefully controlled
- Overhead is minimized
- Hardware resources are sufficient
Sequential merge sort wins when:
- Input size is small
- Simplicity matters
- Parallel overhead dominates
Final Thought
Parallel merge sort is not a magic replacement for sequential merge sort. It is a carefully engineered optimization, not a universal upgrade.
This experiment highlights an important lesson in computer science:
Parallelism is a trade-off, not a guarantee.
Understanding when parallel algorithms help — and why they sometimes don’t — is far more valuable than simply knowing how to implement them.
That difference between theory and practice is where real systems thinking begins.
Related Articles
Why Your APIs Feel Slow (Even When They Aren’t)
UNDERSTANDING THE GAP BETWEEN ACTUAL PERFORMANCE AND PERCEIVED LATENCY In previous parts [https://medium.com/@akshatjme/observability-you-cant-fix-what-you-can...
Load Testing: Why Most Developers Do It Wrong
WHY TESTING FOR STABILITY OFTEN HIDES THE REAL LIMITS OF YOUR SYSTEM In previous parts, we explored how systems behave under pressure. Load testing is meant t...
The Hidden Cost of Synchronous Systems
WHY WAITING FOR EVERY STEP TO FINISH CAN QUIETLY SLOW DOWN YOUR ENTIRE BACKEND In previous parts, we explored how system design choices affect performance. On...