How Timsort Beats QuickSort in Real-World Scenarios
When it comes to sorting algorithms, QuickSort often gets the spotlight for its elegance and average-case performance of O(n log n). But in practice, the real world isn’t made up of purely random data it’s often partially sorted, structured, or patterned.
And that’s where Timsort shines.
You might not know it, but if you’ve ever called sorted() in Python or used Arrays.sort() for objects in Java, you’ve already relied on Timsort a hybrid algorithm that consistently outperforms QuickSort in everyday scenarios.
What Is Timsort?
Timsort was designed in 2002 by Tim Peters for Python. It’s a hybrid of Merge Sort and Insertion Sort, built around one key observation:
Real-world data tends to have existing order and we can take its advantage.
Timsort detects small sequences in the data that are already sorted, called runs, and then merges them efficiently.
In other words, it doesn’t start sorting from scratch it builds on what’s already sorted.
Why Timsort Outperforms QuickSort in Practice
Let’s break it down with a few key differences:
1. Timsort Takes Advantage of Natural Runs
QuickSort treats all input the same, whether it’s sorted, reversed, or random.
Timsort, on the other hand, scans through the array first to find runs consecutive elements that are already sorted (either ascending or descending).
Example:
data = \[1, 2, 3, 7, 6, 5, 8, 9\]Timsort identifies [1, 2, 3] as one run and [7, 6, 5] (which it reverses) as another, minimizing the work needed later.
This drastically reduces comparisons and swaps for partially sorted data a common real-world case.
2. Hybrid Strategy = Adaptive Performance
Timsort combines Insertion Sort (great for small data sets) and Merge Sort (excellent for large, stable sorting).
- For small runs (typically 32–64 elements), it uses Insertion Sort extremely fast due to cache locality.
- It then merges these runs using Merge Sort logic.
This hybrid approach adapts dynamically based on input something QuickSort doesn’t do.
3. Stability Matters
QuickSort is not stable equal elements may change their relative order after sorting.
Timsort, being based on Merge Sort, is stable.
This is crucial in many real-world applications:
- Sorting lists of records (e.g., students with the same grade)
- Multi-level sorts (e.g., sort by name, then by age)
Stable sorting ensures predictable, consistent results a must-have for production-grade systems.
4. Worst-Case Behavior
QuickSort has an O(n²) worst case (e.g., when the array is already sorted and a poor pivot is chosen).
Timsort’s worst case is O(n log n) guaranteed.
That reliability makes it safer for large-scale or mission-critical applications, where unpredictable performance spikes aren’t acceptable.
🚀 Real-World Performance: Where Timsort Wins
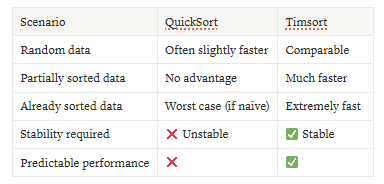
In most practical workloads like user data, logs, or sorted database columns Timsort outperforms QuickSort both in speed and reliability.
Full Python Implementation of Timsort
\# -------------------------------
\# Timsort Implementation in Python
\# -------------------------------
MIN\_RUN = 32 # Default minimum run size used in Python's timsort
def insertion\_sort(arr, left, right):
"""Performs insertion sort on a subsection of the array."""
for i in range(left + 1, right + 1):
key\_item = arr\[i\]
j = i - 1
# Move elements greater than key\_item one position ahead
while j >= left and arr\[j\] > key\_item:
arr\[j + 1\] = arr\[j\]
j -= 1
arr\[j + 1\] = key\_item
def merge(arr, left, mid, right):
"""Merges two sorted subarrays: arr\[left:mid+1\] and arr\[mid+1:right+1\]."""
len1, len2 = mid - left + 1, right - mid
left\_part = arr\[left:mid + 1\]
right\_part = arr\[mid + 1:right + 1\]
i = j = 0
k = left
# Merge the two halves
while i < len1 and j < len2:
if left\_part\[i\] <= right\_part\[j\]:
arr\[k\] = left\_part\[i\]
i += 1
else:
arr\[k\] = right\_part\[j\]
j += 1
k += 1
# Copy remaining elements
while i < len1:
arr\[k\] = left\_part\[i\]
i += 1
k += 1
while j < len2:
arr\[k\] = right\_part\[j\]
j += 1
k += 1
def timsort(arr):
"""Main Timsort function."""
n = len(arr)
# Step 1: Sort small subarrays using insertion sort
for start in range(0, n, MIN\_RUN):
end = min(start + MIN\_RUN - 1, n - 1)
insertion\_sort(arr, start, end)
# Step 2: Merge sorted runs using merge sort logic
size = MIN\_RUN
while size < n:
for left in range(0, n, 2 \* size):
mid = min(n - 1, left + size - 1)
right = min((left + 2 \* size - 1), n - 1)
if mid < right:
merge(arr, left, mid, right)
size \*= 2
return arr
\# -------------------------------
\# Example Usage
\# -------------------------------
if \_\_name\_\_ == "\_\_main\_\_":
import random
# Create a partially sorted array
data = sorted(random.sample(range(1, 100), 20))
data\[5:10\] = reversed(data\[5:10\]) # Add some disorder
print("Original array:")
print(data)
sorted\_data = timsort(data.copy())
print("\\\\nSorted array:")
print(sorted\_data)Why QuickSort Still Has Its Place
Despite Timsort’s dominance in high-level languages, QuickSort remains valuable:
- It’s simpler and easy to implement.
- It uses less memory (in-place sorting).
- It’s still often the go-to in low-level or memory-constrained environments.
So while Timsort is better for general-purpose, production-grade sorting, QuickSort remains strong in algorithmic education and embedded systems.
Tags
Related Articles
Why Your APIs Feel Slow (Even When They Aren’t)
UNDERSTANDING THE GAP BETWEEN ACTUAL PERFORMANCE AND PERCEIVED LATENCY In previous parts [https://medium.com/@akshatjme/observability-you-cant-fix-what-you-can...
Load Testing: Why Most Developers Do It Wrong
WHY TESTING FOR STABILITY OFTEN HIDES THE REAL LIMITS OF YOUR SYSTEM In previous parts, we explored how systems behave under pressure. Load testing is meant t...
The Hidden Cost of Synchronous Systems
WHY WAITING FOR EVERY STEP TO FINISH CAN QUIETLY SLOW DOWN YOUR ENTIRE BACKEND In previous parts, we explored how system design choices affect performance. On...